


Last Updated on August 17, 2023 by Mayank Dham

In the present era, our dependence on data is significant, and to effectively handle data, we employ a database management system, often referred to as DBMS. Within this framework, numerous transactions occur concurrently. Transactions represent the operations we undertake, and due to the simultaneous nature of these transactions, the challenge arises of effectively coordinating them to avoid interference during execution. To address such issues, scheduling algorithms come into play, offering various types of schedules. As we delve deeper into this article, we will explore the classification of strict schedules and delve into further details.
What is a Schedule?
A schedule denotes the arrangement of transactional operations. Scheduling comes into effect when multiple transactions are concurrently executed. The sequencing of these processes is orchestrated to prevent conflicts and ensure proper timing of transactions. It upholds the sequence of operations within each transaction.
Which Schedule is Categorised as a Strict Schedule?
The answer to the above question is the recoverable schedule. We can understand the recoverable schedule as the schedule where the current transaction is committed only after all the transactions from which the current transaction is reading are committed. They are known as recoverable because we can recover the system in case of transaction failure to the last committed state by suing the redo and undo statements. And there is no room for change in these rules and because of this, it is categorized as a strict schedule.
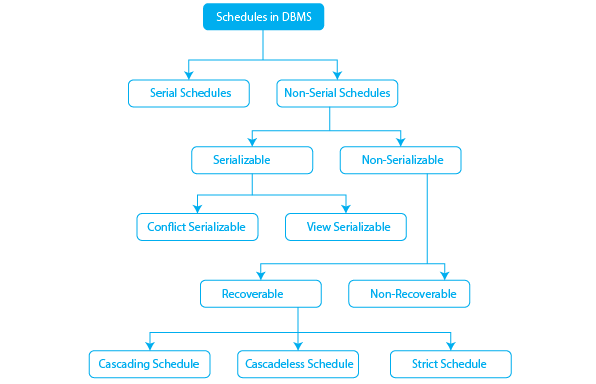
Types of Schedules
There are mainly two types of schedules and they can be further classified into various types. The two types are:
- Serial Schedule
- Non-Serial Schedule
Serial Schedule
As the name suggests serial schedules are those types of schedules that work in serial order means that in order for a transaction to start all the previous transactions must have been completed. At a time only one transaction can run as the other will not run till it is not completed.
Non-Serial Schedule
By the name you can get the idea that they are not doing what serial schedules are doing. They can execute any number of transactions at any time without waiting for any other transactions. Unlike serial schedules, they do not have to wait for the previous transaction to finish in order to start a new transaction.
Serializability
It can be understood as a technique that is able to check which of all non-serial schedules are maintaining the consistency of the database. There are many methods to achieve this with non-serial schedules as serial schedules are always serializable.
To learn more about reliability and above mentioned types of schedules you can refer to Serializability in DBMS.
Recoverable Schedule ini DBMS
These are included in the nonserial schedule. These are the type of schedules that are very helpful in case of transaction failure as by the name you can assume that we can recover the state of the database in this transaction. So when a transaction fails you can recover the last committed state of the database where the transaction was started or last committed by using the undo-redo operations.
| T1 | T2 |
|---|---|
| R(A) | |
| W(A) | |
| W(A) | |
| R(A) | |
| commit | |
| commit |
The above is a recoverable schedule as T1 commits before T2 so the T2 will read the correct value.
The recoverable schedules are categorized into three parts.
- Cascading Schedule
- Cascadeless schedule
- Strict Schedule
Cascading Schedule in DBMS
In this schedule when there is a failure in one transaction and it has rolled back then all the other dependent transactions on that transaction will have to roll back.
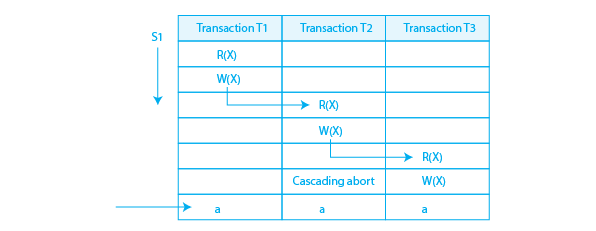
Here Transaction T3 depends on T2 and the T2 depends on T1 so the failure in T1 leads to T2 rolling back and is similar for T3.
Cascadeless Schedule in DBMS
In this if a transaction fails it does not lead the other transactions to fail as here no transaction is not allowed to read from any other transaction unless the last transaction in execution is committed or aborted. It saves CPU time and also prevents the Cascadeless Schedule. As there is no rolling back. We achieve this with the help of locks and various other synchronization methods to prevent the transaction from reading the data of other in-progress transactions.
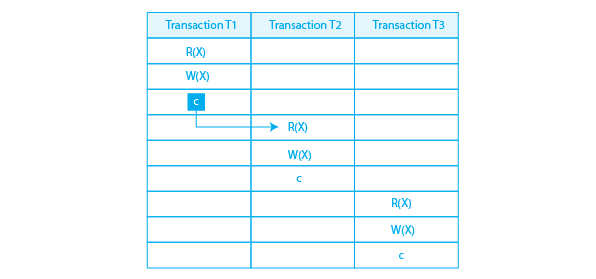
Here the T2 will read the value after T1 is committed and the same with T3 hence it is a cascade-less schedule.
Strict Schedule in DBMS
A strict schedule is a schedule in which the order of transactions is preserved exactly as specified by the program or user. Strict schedules are usually not efficient, but they guarantee the integrity and consistency of the data.
| T1 | T2 |
|---|---|
| R(X) | |
| R(X) | |
| W(X) | |
| commit | |
| W(X) | |
| R(X) | |
| commit |
Here the T2 writes the read value of T1 only after T1 is committed hence it is a strict schedule.
Applications of Strict Schedule in DBMS
There are many applications for strict schedules some of which are mentioned below.
- They are used to maintain the serializability of the transaction. It will ensure that the final state of the database is the same as that of the starting.
- They are used for deadlock avoidance as deadlock occurs when two or more transactions are waiting for resources but with strict schedules, we can implement strict rules to ensure that it does not happen.
- The database can be recovered to last consistent state with the help of strict schedules.
Conclusion
The concept of a strict schedule in DBMS holds significance in maintaining data integrity and consistency. A strict schedule ensures that transactions are executed in a manner that eliminates the possibility of conflicts and preserves the accuracy of the database. Through its stringent adherence to the order of operations, a strict schedule in DBMS contributes to the reliable and secure management of data in complex and dynamic environments.
Frequently Asked Questions
Below are some of the frequently asked questions about the strict schedule.
1. What do you mean by concurrent schedule?
Concurrent schedule refers to the type of schedule where multiple transactions can run simultaneously.
2. What do you understand by dirty read?
It is a condition when a transaction has read the data that has been modified by the uncommitted transaction.
3. What do you mean by write operation?
This is an operation that modifies the data in the database.
4. What is conflict in DBMS?
A conflict is a situation in which two transactions access the same data item and at least one of them modifies it.