


Last Updated on June 19, 2023 by Mayank Dham

In today’s data-driven world, businesses and researchers are constantly seeking ways to uncover hidden patterns and valuable insights from vast amounts of information. One powerful technique that has emerged to address this challenge is association rule mining. Among the various algorithms used for association rule mining, the Apriori algorithm stands out as a fundamental and widely adopted approach. In this article, we delve into the workings of the Apriori algorithm, its applications, and its significance in extracting meaningful associations from data.
History of Apriori Algorithm
Developed by R. Agrawal and R. Srikant in 1994, the Apriori algorithm is an influential algorithm used for discovering frequent item sets in large datasets. Its primary objective is to identify associations or relationships between items based on their co-occurrence patterns. The algorithm follows a bottom-up approach and utilizes a breadth-first search strategy to traverse the search space efficiently.
Key Steps of the Apriori Algorithm
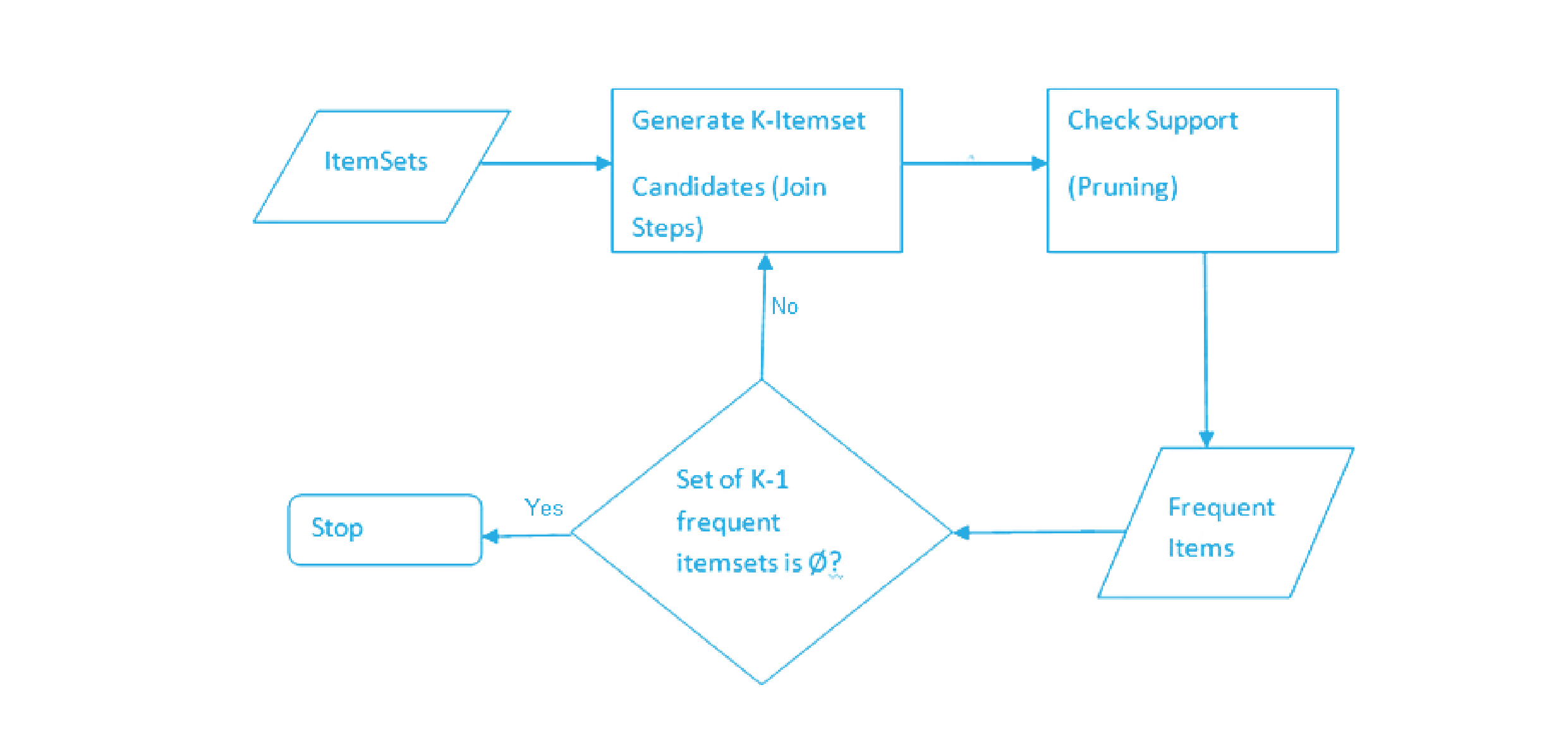
1. Generating frequent itemsets
The algorithm starts by scanning the entire dataset to identify the individual items and their frequencies. It then generates frequent itemsets, which are sets of items that appear together in the dataset above a user-defined minimum support threshold. This step helps filter out infrequent and less relevant itemsets, reducing the computational complexity in subsequent iterations.
2. Joining and pruning
In this step, the algorithm generates larger itemsets by joining smaller frequent itemsets. The join operation exploits the "Apriori property," which states that if an itemset is infrequent, any of its supersets will also be infrequent. The pruning step eliminates candidate itemsets that fail to meet the minimum support threshold, further reducing the search space.
3. Repeating the process
The previous steps are iterated until no more frequent itemsets can be generated or until the desired level of association is achieved. At each iteration, the algorithm progressively increases the size of the itemsets, exploring higher-order associations.
Components of the Apriori algorithm
The given three components comprise the apriori algorithm.
- Support
- Confidence
- Lift

As previously stated, a large database containing a significant number of transactions is required. Assume there are 4000 client transactions in a Big Bazar. You must compute the Support, Confidence, and Lift for two items, say Biscuits and Chocolate. Customers typically purchase these two things together.
Out of 4000 transactions, 400 have Biscuits, 600 contain Chocolate, and 200 of these 600 transactions contain both Biscuits and Chocolate. We will determine the support, confidence, and lift using this data.
Support
The default popularity of any product is referred to as support. The support is calculated as a quotient of the number of transactions that comprise that product divided by the total number of transactions. As a result, we receive
Support (Biscuits) = (Biscuit transactions) / (Total transactions) = 400/4000 = 10%.
Confidence
Customers’ confidence refers to the probability that they purchased both biscuits and chocolates at the same time. To calculate the confidence, divide the number of transactions that include both biscuits and chocolates by the total number of transactions.
As a result, Confidence = (Transactions Relating to Both Biscuits and Chocolate) / (Total Transactions Relating to Biscuits) = 200/400 = 50%.
This suggests that 50% of people who purchased biscuits also purchased chocolates.
Lift
Consider the preceding example: lift refers to the increase in the ratio of chocolate sales when you sell biscuits. The lift mathematical equations are presented below.
Lift = (Biscuits – chocolates) / (Biscuits Support) = 50/10 = 5
It indicates that the likelihood of individuals purchasing both biscuits and chocolates together is five times greater than the likelihood of purchasing only biscuits. If the lift value is less than one, it indicates that buyers are unlikely to purchase both things simultaneously. The better the combo, the higher the value.
Apriori Algorithm in Data Mining
An example will help us grasp this method.
Consider the following Big Bazar scenario: P = Rice, Pulse, Oil, Milk, Apple. The database contains six transactions, with 1 representing the presence of the product and 0 representing its absence.
All subsets of a frequent item set must be frequent. The subsets of an infrequent item set must be infrequent. Fix a threshold support level. In our case, we have fixed it at 50 percent.
Step 1
- Make a frequency table of all the products that appear in all the transactions.
- Now, shorten the frequency table to add only those products with a threshold support level of over 50 percent.
- We found the given frequency table.
Step 2
- Create pairs of products such as RP, RO, RM, PO, PM, OM. You will get the given frequency table.
Step 3
- Implementing the same threshold support of 50 percent and consider the products that are more than 50 percent. In our case, it is more than 3.
- Thus, we get RP, RO, PO, and PM.
Step 4
-
Now, look for a set of three products that the customers buy together. We get the given combination.
-
RP and RO give RPO.
-
PO and PM give POM.
Step 5
- Calculate the frequency of the two itemsets, and you will get the given frequency table.
- If you implement the threshold assumption, you can figure out that the customers’ set of three products is RPO.
- We have considered an easy example to discuss the apriori algorithm in data mining. In reality, you find thousands of such combinations.
How can we improve the efficiency of the Apriori Algorithm?
There are various methods used for the efficiency of the Apriori algorithm
1. Hash-based itemset counting
In hash-based itemset counting, you need to exclude the k-itemset whose equivalent hashing bucket count is less than the threshold because it is an infrequent itemset.
2. Transaction Reduction
In transaction reduction, a transaction not involving any frequent X items becomes less valuable in subsequent scans.
Advantages of Apriori Algorithm
- It is used to calculate large item sets.
- Simple to understand and apply.
Disadvantages of Apriori Algorithm
- Apriori algorithm is an expensive method to find support since the calculation has to pass through the whole database.
- Sometimes, you need a huge number of candidate rules, so it becomes computationally more expensive.
Applications of the Apriori Algorithm
1. Market basket analysis
The Apriori algorithm finds extensive application in market basket analysis, where it helps uncover associations between products frequently purchased together. Retailers can utilize these associations to optimize product placement, cross-selling, and targeted marketing strategies.
2. Web usage mining
By applying the Apriori algorithm to web log data, valuable insights can be derived regarding the browsing behavior of users. This information can be leveraged to enhance website navigation, improve recommendations, and personalize user experiences.
3. Healthcare
In the healthcare domain, the Apriori algorithm can be employed to identify patterns in patient records, such as disease co-occurrence or medication interactions. These insights aid in disease prediction, treatment planning, and improving healthcare outcomes.
Significance of the Apriori Algorithm
The Apriori algorithm’s significance lies in its ability to efficiently mine association rules from large datasets, even when the number of possible items is enormous. By focusing on frequent item sets, the algorithm effectively prunes the search space, thereby reducing computational complexity. Furthermore, the generated association rules provide valuable insights into customer behavior, user preferences, and co-occurrence patterns, enabling businesses to make informed decisions and drive strategic initiatives.
Conclusion
The Apriori algorithm remains a cornerstone in the field of association rule mining, offering an effective and widely adopted approach to discovering meaningful associations between items. With its ability to efficiently handle large datasets and extract valuable insights, the algorithm finds applications in diverse domains such as retail, web usage analysis, and healthcare. As data continues to grow exponentially, the Apriori algorithm will continue to play a vital role in unraveling the hidden patterns that lie within, empowering organizations and researchers alike to make data
Frequently Asked Questions (FAQs)
Q1. What is the minimum support threshold in the Apriori algorithm, and why is it important?
The minimum support threshold is a user-defined parameter in the Apriori algorithm. It determines the minimum frequency or occurrence required for an item to be considered "frequent." This threshold is essential because it filters out infrequent itemsets, reducing the search space and computational complexity. By setting an appropriate minimum support threshold, analysts can focus on discovering associations that are statistically significant and relevant to their analysis.
Q2. Can the Apriori algorithm handle datasets with high dimensionality?
The Apriori algorithm’s performance can be affected by high-dimensional datasets. As the number of items or attributes increases, the search space expands exponentially, leading to a significant increase in computational time. To mitigate this issue, dimensionality reduction techniques or alternative algorithms specifically designed for high-dimensional data, such as FP-Growth, can be considered. These algorithms offer improved efficiency and scalability for analyzing datasets with numerous attributes.
Q3. Are there any limitations to the Apriori algorithm?
While the Apriori algorithm is widely used, it does have some limitations. One limitation is its dependence on the minimum support threshold, which must be set appropriately. Selecting an extremely low threshold can lead to an excessive number of frequent items, while setting it too high may result in the omission of potentially valuable associations. Additionally, the algorithm may face challenges with large datasets due to the combinatorial explosion of item sets. However, optimization techniques and parallel computing can help mitigate these limitations.
Q4. How does the Apriori algorithm handle missing values in datasets?
The Apriori algorithm assumes complete and consistent datasets without missing values. If a dataset contains missing values, various strategies can be employed to handle them before applying the algorithm. One common approach is to impute the missing values using techniques such as mean imputation, regression imputation, or hot-deck imputation. By replacing missing values with estimated or interpolated values, the dataset can be prepared for use with the Apriori algorithm.
Q6. Can the Apriori algorithm be used for real-time or streaming data analysis?
The traditional Apriori algorithm is primarily designed for batch processing and may not be suitable for real-time or streaming data analysis. The algorithm requires a complete dataset to identify frequent items and associations. However, there are extensions and variations of the Apriori algorithm, such as the incremental Apriori algorithm or sliding window techniques, that aim to address the challenges of real-time data. These modified algorithms adapt the Apriori approach to incrementally update and maintain frequent item sets as new data arrives, allowing for real-time or near-real-time association rule mining.