


Last Updated on July 24, 2023 by Mayank Dham

This article aims to aid you in understanding how to find duplicate in linked list. Familiarity with linked lists can be advantageous for succeeding in IT interviews, as a solid understanding of these data structures is often sought after during coding assessments. Without further ado, let’s delve into our topic of finding duplicates in a linked list.
How to find duplicate in Linked List?
In this question, we are given a singly linked list. We have to count the number of duplicate nodes in the linked list
Problem Statement Understanding To Find Duplicate Elements In Linked List
Let’s first understand the problem statement with help of examples.
Suppose the given list is:

We have to count the number of duplicate nodes in the list.
From the above given linked list, we can see that:
- Count of each 1 and 8 is 2 in the linked list.
- While the count of 7 is 1 in the linked list.
So, we can say that duplicates of 1 and 8 exist in the linked list, 1 duplicate each of 1 and 8 exists in the linked list. So, we will return the count of duplicate node in the linked list as (1+1) = 2.
If the given linked list is:

For the above-linked list, we can see that:
- Count of each 1, 2, 3 is 2 in the linked list.
- The count of 5 is 3.
- While the count of 4 is 1 in the linked list.
So, we can say that duplicates of 1, 2, 3, and 5 exist in the linked list, 1 duplicate each of 1, 2, and 3 exist and 2 duplicates of 5 exist. So, we will return the count of duplicate node in the linked list as (1+1+1+2) = 5.
Now, I think it is clear from the examples what we have to do with the problem. So let’s move to approach.
Before jumping to approach, just try to think how can you approach this problem?
It’s okay if your solution is brute force, we will try to optimize it together.
We will first make use of simple nested list traversal to find the duplicates, although it will be a brute-force approach, it is necessary to build the foundation.
Let us have a glance at brute force approaches.
Approach and Algorithm (Brute Force) To Find Duplicate Elements In Linked List
The approach is going to be pretty simple.
- We will create a variable count and initialize it to 0.
- Now, we will traverse through the list, and for every node, we will traverse from its next node to the end of the list whenever we will find a match, we will increase the counter and will break out of the loop. Basically here what we are trying to find out is that is this particular node duplicate or not.
This method has a time complexity of O(n2) as it is using nested traversal.
Can we do better?
Yes. We can do better. We can do it in O(n) with the help of hashing.
Let us see the efficient approach.
Approach (Hashing) To Find Duplicate Elements In Linked List
In this approach, we will use hashing.
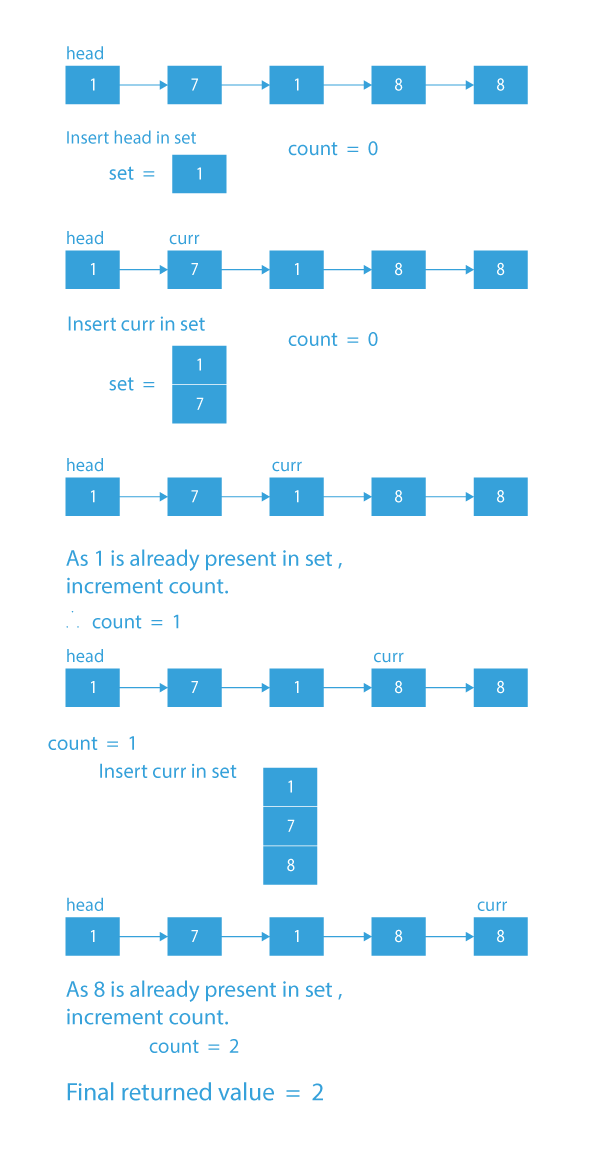
- Firstly, we will create an unordered set, and we will insert the data of the head in the set.
- We will also create a counter whose initial value will be 0.
- Now, we will traverse through the list, starting from the next node, and for every node, we will check if that node is already present in the set or not. If it is present, we will increment the counter. We will also keep inserting the nodes, that we are traversing, in the set.
Algorithm To Find Duplicate Elements In Linked List
- Base Case – If the head is NULL, return 0.
- Create an unordered set, say s, and a variable count with an initial value of 0.
- Insert the head → data in the set.
- Traverse from the next node of the head till the end of the list.
- In every iteration, check if the node’s data is already present in the set or not. If present, increment the count.
- Insert the current node’s data in the set.
- In the end, return the count variable.
Dry Run To Find Duplicate Elements In Linked List
Code Implementation
#include<stdio.h>
#include<stdlib.h>
struct Node {
int data;
struct Node* next;
};
// Function to insert a node at the beginning
void insert(struct Node** head, int item)
{
struct Node* temp = (struct Node*)malloc(sizeof(struct Node));
temp->data = item;
temp->next = *head;
*head = temp;
}
// Function to count the number of
// duplicate nodes in the linked list
int countNode(struct Node* head)
{
int count = 0;
while (head->next != NULL) {
// Starting from the next node
struct Node *ptr = head->next;
while (ptr != NULL) {
// If some duplicate node is found
if (head->data == ptr->data) {
count++;
break;
}
ptr = ptr->next;
}
head = head->next;
}
// Return the count of duplicate nodes
return count;
}
// Main function
int main()
{
struct Node* head = NULL;
insert(&head, 5);
insert(&head, 7);
insert(&head, 5);
insert(&head, 4);
insert(&head, 7);
int ans = countNode(head);
printf("%d", ans);
return 0;
}
#include <iostream>
#include <unordered_set>
using namespace std;
struct Node {
int data;
Node* next;
};
void insert(Node** head, int item)
{
Node* temp = new Node();
temp->data = item;
temp->next = *head;
*head = temp;
}
int countNode(Node* head)
{
if (head == NULL)
return 0;;
unordered_set<int> s;
s.insert(head->data);
int count = 0;
for (Node *curr=head->next; curr != NULL; curr=curr->next) {
if (s.find(curr->data) != s.end())
count++;
s.insert(curr->data);
}
return count;
}
int main()
{
Node* head = NULL;
insert(&head, 8);
insert(&head, 8);
insert(&head, 1);
insert(&head, 7);
insert(&head, 1);
cout << countNode(head);
return 0;
}
import java.util.HashSet;
public class PrepBytes
{
static class Node
{
int data;
Node next;
};
static Node head;
static void insert(Node ref_head, int item)
{
Node temp = new Node();
temp.data = item;
temp.next = ref_head;
head = temp;
}
static int countNode(Node head)
{
if (head == null)
return 0;;
HashSet<integer>s = new HashSet<>();
s.add(head.data);
int count = 0;
for (Node curr=head.next; curr != null; curr=curr.next)
{
if (s.contains(curr.data))
count++;
s.add(curr.data);
}
return count;
}
public static void main(String[] args)
{
insert(head, 8);
insert(head, 8);
insert(head, 1);
insert(head, 7);
insert(head, 1);
System.out.println(countNode(head));
}
}
class Node:
def __init__(self, data = None, next = None):
self.next = next
self.data = data
head = None
def insert(ref_head, item):
global head
temp = Node()
temp.data = item
temp.next = ref_head
head = temp
def countNode(head):
if (head == None):
return 0
s = set()
s.add(head.data)
count = 0
curr = head.next
while ( curr != None ) :
if (curr.data in s):
count = count + 1
s.add(curr.data)
curr = curr.next
return count
insert(head, 8)
insert(head, 8)
insert(head, 1)
insert(head, 7)
insert(head, 1)
print(countNode(head))
Output
2
Time Complexity To Find Duplicate Elements In Linked List: O(n), as list traversal is needed.
This article will help you to understand how to find duplicate in linked list. There is a lot of stuff to prepare for the interviews but data structures and algorithms are the most important topics as these are the must needed skills for any company. This is an important question when it comes to coding interviews. If you want to solve more questions on Linked List, which is curated by our expert mentors at PrepBytes, you can follow this link Linked List.
**Conclusion**
The process of counting duplicates in a linked list using hashing is an efficient algorithm that can be helpful in identifying and handling duplicate elements effectively. By utilizing a hash table, we can keep track of unique elements as we traverse the linked list, and whenever a duplicate is encountered, we can take appropriate actions based on the requirements (e.g., printing, deleting, or marking the duplicate node). This approach ensures that the duplicate elements are managed with a time complexity of O(n), where n is the number of nodes in the linked list.
FAQ Related To Find Duplicate Elements In Linked List
**Q1. What is the time complexity for searching for an element on a Linked List?**
Since there is no way of accessing any node without visiting its previous node, we have to traverse the entire Linked List every time we need to search for an element. Therefore, the worst-case time complexity is O(N) where N is the number of elements in a Linked List.
**Q2. How do you find duplicates in a linked list?**
We traverse the whole linked list. For each node, we check in the remaining list whether the duplicate node exists or not. If it does then we increment the count.
**Q3. Is a linked list dynamic?**>
Linked List is a dynamic structure, which means the list can grow or shrink depending on the data making it more powerful and flexible than Arrays. Unlike Arrays, Linked List is not stored in a contiguous memory location. Each element in the list is spread across the memory and are linked by the pointers in the Node.
**Q4. Does the order of elements matter in counting duplicates?**
The order of elements does not matter when counting duplicates using the hashing approach. The hash table stores unique elements, and the duplicates are identified irrespective of their position in the linked list.
**Q5. What if the linked list is a circular linked list?**
For a circular linked list, you can use the same hashing approach to count duplicates. The traversal will continue until the loop is completed, and duplicates will be identified and processed accordingly.