


Last Updated on November 28, 2023 by Ankit Kochar

Embarking on the journey of partitioning a linked list around a given value while preserving the original order is a compelling exploration into the realm of linked list manipulation. This task involves rearranging the elements of a linked list so that all nodes with values less than a specified value appear before those greater than or equal to it, all while maintaining the initial order of elements. In this guide, we will unravel the intricacies of this operation, exploring algorithms and techniques to seamlessly partition a linked list around a chosen value while respecting the original order. Let’s dive into the fascinating world of linked list manipulation and partitioning!
Partitioning a linked list around a given value
In this problem, given a linked list and a value X, we are required to partition it such that all nodes less than X come before nodes greater than or equal to x.
Note: You should maintain the original relative order of the nodes in each of the two partitions.
Let’s understand the problem statement with the help of examples.
If the given linked list is:

It means that we have to move all nodes smaller than 3 before the nodes have values greater than or equal to 3. Also, while partitioning the linked list around value 3, the original relative order of the nodes in each of the two partitions should be maintained.
So our final resultant linked list after partitioning will look like this:

This statement maintains the original relative order of the nodes in each of the two partitions implies that while partitioning, the nodes in each of the two partitions should be in the same order as they are present in the original linked list.
- From the above-linked list, we can see that 1, 2, and 2 will come in the first partition(nodes smaller than X) and 4, 3, and 7 will come in the second partition(nodes greater than or equal to X).
- If we carefully compare the resultant linked list and the original linked list we can clearly see that 1, 2, and 2, the nodes of the first partition are in the same order in the resultant list as they were in the original linked list (2 is occurring after 1 and another 2 is occurring after 2). Similarly, the nodes of the second partition 4, 3, and 7 are also in the same order as they were in the original linked list (3 is occurring after 4 and another 5 is occurring after 3).
Explanation: In the resultant linked list, first there will be the elements of the first partition (elements or nodes smaller than X) and then there will be the elements of the second partition (elements greater than or equal to X). Also, both partitions will preserve the order from the original linked list.
Now I think from the above example the problem is clear, we will have to now think of how we can approach this problem.
Approach to partition a linked list around a given value
As we need all the nodes having a value smaller than X before nodes having a value greater than or equal to X, so we will have to divide the original linked list into two sections:
- A list of nodes with values less than X and,
- A list of nodes with values higher than or equal to X.
Then, after diving into the original linked list, we’ll use pointers to stitch them back together after the division such that all the nodes having smaller value than X comes before nodes having a greater value equal to X.
The algorithm in brief:
We will traverse the original linked list as normal, and we will select in which linked list a node should belong to based on its value.
- If a node’s value is less than X, it will be appended to the low-container list, which keeps track of nodes with values less than X.
- Otherwise, it will be appended to the high-container list, which keeps track of nodes with values greater than or equal to X.
Finally, after traversing, we’ll sew the end node of the first linked list (the low-container list) to the head node of our second list (the high-container list). This way, we can maintain the order of elements in the list.
After the complete traversal of the original linked list, the low-container list will have all the nodes having value smaller than X, while the high-container list will have all the nodes having values greater than or equal to X.
A few buffers will be required to maintain track of the partitioned lists.
- new_Head: Head of the new modified linked list.
- low_Head: Head of low-container linked list.
- high_Head: Head of high-container linked list.
- less: A pointer that will help us in linking every node with the value lower than X together, this way we will get the low-container list. It will act as an iterator for the low-container linked list.
- more: A pointer which will help us in linking every node with the value higher or equal to the X together, this way we will get the high-container list. It will act as an iterator for the high-container linked list.
Algorithm to partition a linked list around a given value
- Check if head == NULL, If true, return NULL.
- Initialize new_Head, low_Head, high_Head, less and more to NULL.
- Begin iterating the original linked list. We’ll try to make two distinct linked lists (low-container list and high-container list) out of the original linked list by just changing the links.
- While traversing the original linked list:
- If a node is having value smaller than X, it will get appended to the end of low-container list.
- If a node is having value greater than or equal to X, it will get appended to the end of high-container list.
- Once the traversal of the original linked list is over, the low-container list will be a list having all the nodes with values smaller than X and the high-container list will contain all the nodes from the original list having values greater than or equal to X.
- The heads of the two linked lists above will both point to the first node of their own lists.
- Finally, all that remains is to stitch the lists back together. The low-container linked list’s last node should point to the head of the high-container linked list.
- We will return the head of high-container list if the low-container list does not exist (the original linked list does not contains any nodes with a value less than X) and if the low-container list exists we will make new_Head point to head of low-container(low_Head) and will return new_Head.
The problem has been solved only by adjusting the links.
Dry Run of partition a linked list around a given value
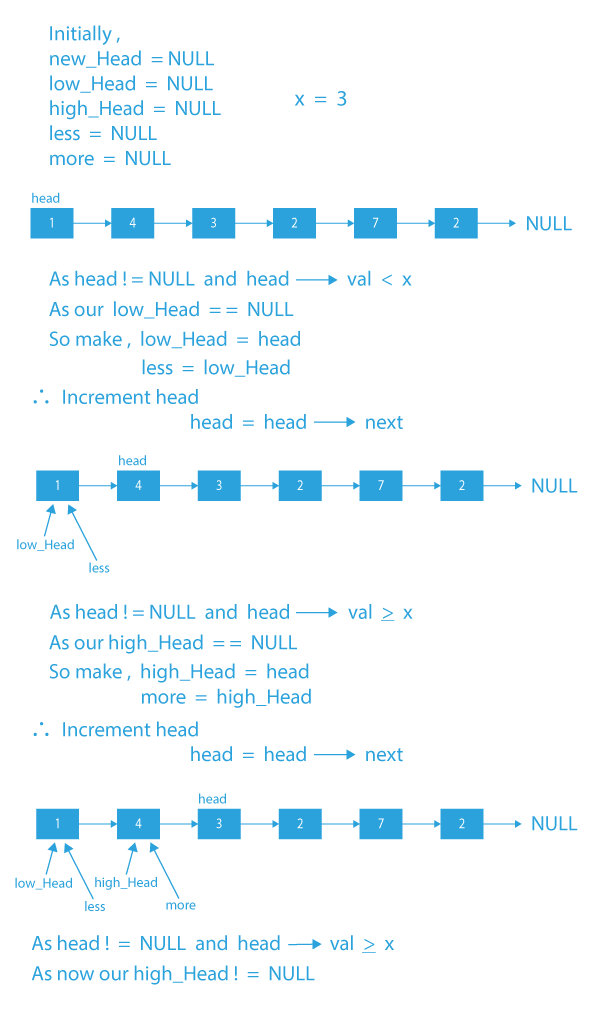
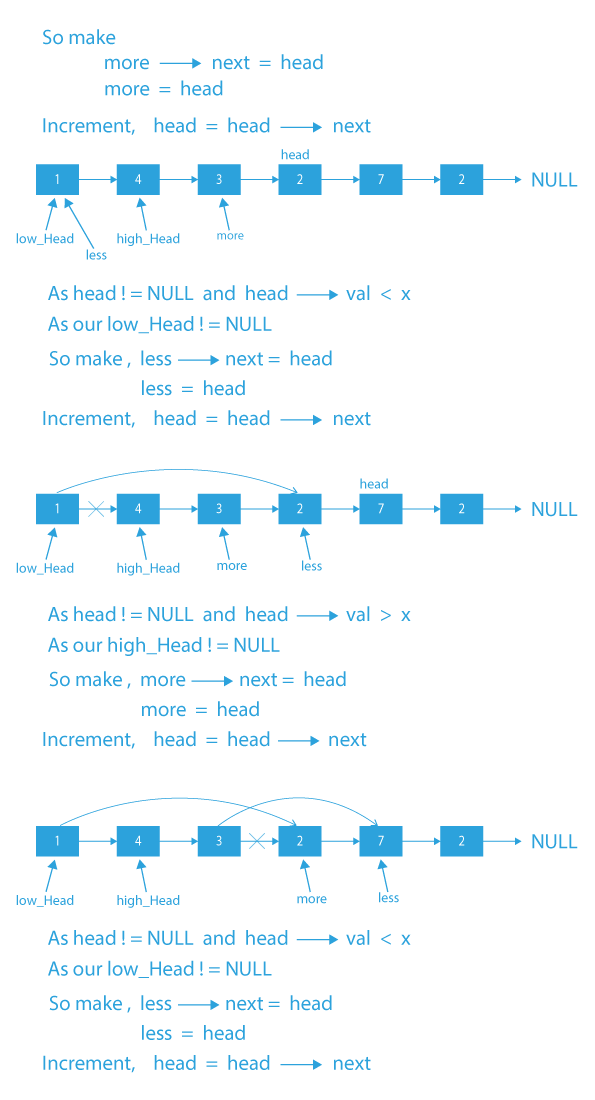
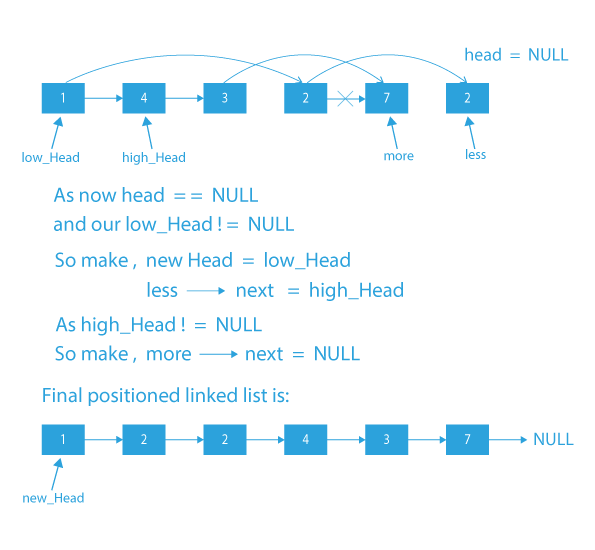
## Code Implementation of partition a linked list around a given value
#includeusing namespace std; // Structure of a node struct node{ int val; struct node* next; node(int x){ val=x; next=NULL; } }; // Return pointer to the produced list. struct node* orderOfList(struct node* head,int x){ if(!head)return head; // return NULL if the linked list is empty // Head of the modified list struct node* new_Head = NULL; // Head of low-container list partition struct node* low_Head = NULL; // Head of high-container list partition struct node* high_Head = NULL; // Itearator of low-container list. struct node* less = NULL; // Iterator of high-container list. struct node* more = NULL; // traverse through the list. while(head){ if(head->val < x){ /* If the node's value is less than x, it should go in low-container. If we haven't set the head of low-container Then, low_Head will be the head.*/ if(!low_Head){ low_Head = head; // and also point the iterator to the beginning. less = low_Head; }else{ less->next = head; /* If the low_Head is already initialized, we are required to point the iterator to point to this node*/ less = head; } }else{ if(!high_Head){ /* initialize if the head of the high-container has not been initialized yet. and point the 'more' iterator to the beginning which is high_Head.*/ high_Head = head; more = high_Head; }else{ /* If high_Head already initialized, point the next field of last node in this list to head*/ more->next = head; // updating the iterator more = head; } } head = head->next; // Update the iterator of the original list. } if(low_Head == NULL){ /* If the first partition of the linked list(low-container) is empty, we just return the high_Head. Also point the last node's next to NULL.*/ new_Head = high_Head; more->next = NULL; }else{ /* if the low_head list exists point the new_Head to low_Head*/ new_Head = low_Head; /* last node of the low-container should point to the high-container's head.*/ less->next = high_Head; if(high_Head){ more->next = NULL; } } return new_Head; } // To traverse through the linked list void list_traversal(struct node* head){ while(head){ cout< val<<" "; head = head->next; } } int main() { struct node* head = new node(1); head->next = new node(4); head->next->next = new node(3); head->next->next->next = new node(2); head->next->next->next->next = new node(7); head->next->next->next->next->next = new node(2); int x = 3; struct node* new_Head = orderOfList(head,x); list_traversal(new_Head); return 0; }
Output
1→2→2→4→3→7
Time Complexity of partition a linked list around a given value: O(N) – we are traversing through the original linked list and only creating 2 linked lists out of it.
**Conclusion**
In conclusion, the process of partitioning a linked list around a given value while preserving the original order is a nuanced operation that combines principles of sorting and linked list manipulation. By carefully traversing the list and reorganizing nodes based on the specified value, the original order is maintained while achieving the desired partition. This task not only calls for a clear understanding of pointers and node manipulation but also highlights the elegance of algorithms in maintaining order within a linked list. As you delve into linked list partitioning, you unlock a powerful skill for efficient data organization in programming.
## FAQs related to partition a linked list around a given value
Below are some of the FAQs related tp Partition a Linked List around a given value:
**Q1: Why would I need to partition a linked list around a given value while preserving the original order?
A1:** Partitioning a linked list around a given value while preserving the original order is often necessary when you want to organize the elements based on a specific criterion without altering their initial sequence. This can be crucial for certain algorithms or data processing tasks.
**Q2: Are there specific algorithms or methods for partitioning a linked list around a given value?
A2:** Yes, there are various algorithms and approaches for partitioning a linked list around a given value while preserving the original order. One common method involves iterating through the list, comparing values, and appropriately reorganizing nodes to achieve the desired partition.
**Q3: How does the time complexity of partitioning a linked list compare to sorting it?
A3:** The time complexity of partitioning a linked list around a given value while preserving the original order can vary depending on the algorithm used. In general, it is likely to be more efficient than a full sorting operation, especially if the original order needs to be maintained.
**Q4: Can partitioning a linked list be performed in-place, or does it require additional data structures?
A4:** Partitioning a linked list can be performed in-place, meaning that the rearrangement of nodes is done within the existing list without requiring additional data structures. This is often achieved through careful manipulation of pointers.
**Q5: What happens if the given value in partitioning is not present in the linked list?
A5:** If the given value is not present in the linked list, the partitioning operation may proceed as usual, with elements less than the specified value appearing before those greater than or equal to it. The absence of the value does not typically disrupt the partitioning process.