


Last Updated on November 4, 2022 by Prepbytes

Introduction
We know that a linked list is a mutable data structure. And it might have duplicate elements in it. We basically have two types of linked lists: one is a sorted linked list and another is an unsorted linked list. Here we will see an approach to remove duplicates from sorted list
Problem Statement on how to remove duplicates from sorted linked list
In this problem, we are given a sorted LinkedList and are asked to remove the duplicate elements present in the list.
Problem Statement Understanding on how to remove duplicates from sorted list.
According to the problem statement, we will be given a sorted linked list that may contain duplicate elements. We need to remove the duplicate elements from the list.
Let’s try to understand the problem with the help of some examples.
If the given input sorted linked list is:

- As we can see in the above list, there are multiple occurrences of elements 10, 12 in the linked list.
- So it means that the list contains duplicates of 10, 12 , and we need to remove these duplicates from the linked list.
- After removing the duplicate elements from the list, the output linked list will be:

If the linked list is: head->11->11->25->40->40->45.
- In this case, as we can see in the above list, 11 and 40 are duplicate elements present more than once in the list.
- After removing the duplicate elements from the list, the output will be head->11->25->40->45.
Some more examples:
Sample Input 1: head->2->2->3->4->7.
Sample Output 1: head->2->3->4->7.
Sample Input 2: head->3->3->7->7->7->11->11->12->15.
Sample Input 2: head->3->7->11->12->15.
Now, I think from the above examples, the problem statement is clear. So let’s see how we will approach it.
Before moving to the approach section, try to think about how you can approach this problem.
- If stuck, no problem, we will thoroughly see how we can approach the problem in the next section.
Let’s move to the approach section.
Approach 1 (Using Hashmaps) on how to remove duplicates from sorted list
Our approach will be simple; we will be using hashmap:
- While traversing the Linked List, for every element, we will check if it is already present in the map or not.
- If it is already present, then we will remove the element from the list.
- Else we will push the element in the hash map and move forward.
This approach will require extra space.
Time complexity: O(n), where n is the number of nodes in the linked list.
Space complexity: O(n), where n is the number of nodes in the linked list.
Although the above approach will work fine, but it requires some extra space. Now the main question is do we necessarily need this extra space? Can we remove duplicates from the sorted linked list without consuming extra space?
- Let’s see in the next section how we can solve this problem without using extra space.
Let’s move to the next approach.
Approach 2 (Using two pointers)on how to remove duplicates from sorted linked list
Our approach will be straightforward:
- We will create a pointer prev that will to the first occurrence of the element and second pointer temp to traverse the linked list.
- If the value of the temp pointer is equal to the prev pointer, temp will move forward and when we find the node whose value is not equal to prev pointer, we will connect the node pointer by prev with the node pointed by temp and move prev pointer to the position of temp and move temp forward.
From the above approach, we can see that we are using constant extra space here.
Time complexity: O(n), where n is the number of nodes in the linked list.
Space complexity: O(1), As constant extra space, is required.
Let’s see another approach that solves this problem in similar time and space complexity using two pointers for the sake of learning.
Approach 3
The idea is very simple:
- Traverse the list using a pointer, say current.
- While traversing the list compare the current node’s value with the value of it’s next node.
- If they are the same, remove the next node.
- Else move forward.
- Keep on doing this till we reach the end of the linked list.
Algorithm on how to remove duplicates from sorted list
- Create a pointer current.
- Traverse the Linked List in a linear fashion.
- For every node, check the next node’s data.
- If they are the same, then delete the current’s next node by changing the current node pointer.
- If they are different, then move current pointer forward (current = current->next).
- Keep on doing this until current->next != NULL or we can say until we reach the end of the linked list.
Dry Run on how to remove duplicates from sorted linked list
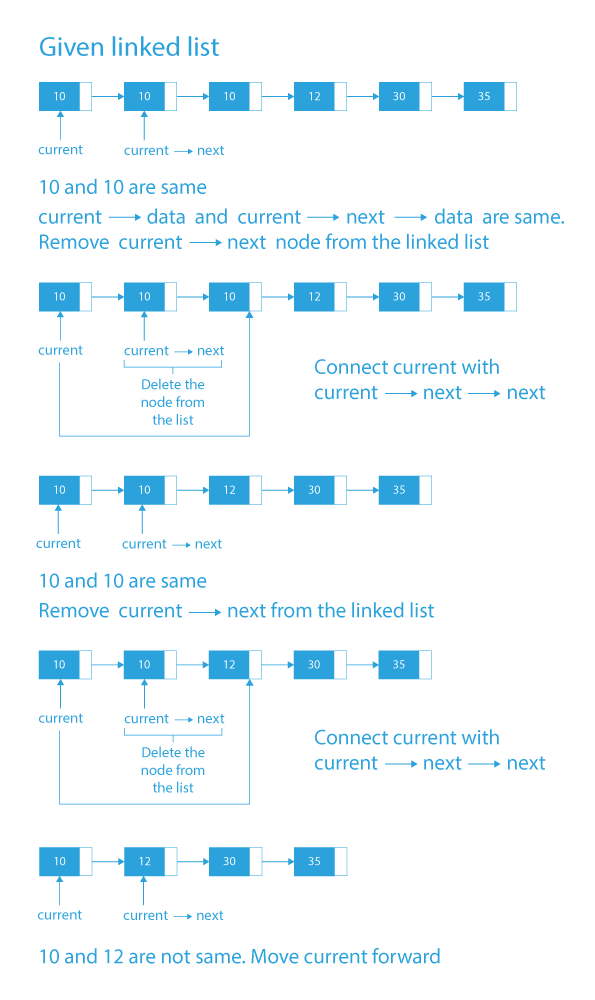
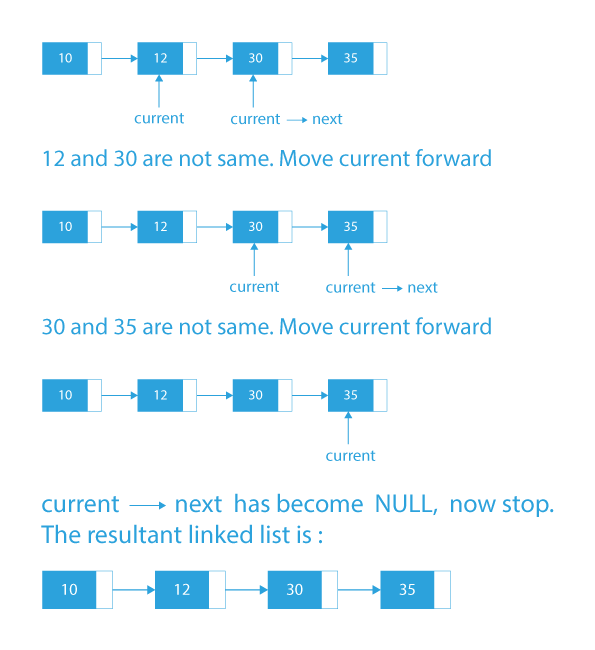
Code Implementation on how to remove duplicates from sorted list
#include<stdio.h>
#include<stdlib.h>
/* Link list node */
struct Node
{
int data;
struct Node* next;
};
/* The function removes duplicates from a sorted list */
void removeDuplicates(struct Node* head)
{
/* Pointer to traverse the linked list */
struct Node* current = head;
/* Pointer to store the next pointer of a node to be deleted*/
struct Node* next_next;
/* do nothing if the list is empty */
if (current == NULL)
return;
/* Traverse the list till last node */
while (current->next != NULL)
{
/* Compare current node with next node */
if (current->data == current->next->data)
{
/* The sequence of steps is important*/
next_next = current->next->next;
free(current->next);
current->next = next_next;
}
else /* This is tricky: only advance if no deletion */
{
current = current->next;
}
}
}
/* UTILITY FUNCTIONS */
/* Function to insert a node at the beginning of the linked list */
void push(struct Node** head_ref, int new_data)
{
/* allocate node */
struct Node* new_node =
(struct Node*) malloc(sizeof(struct Node));
/* put in the data */
new_node->data = new_data;
/* link the old list off the new node */
new_node->next = (*head_ref);
/* move the head to point to the new node */
(*head_ref) = new_node;
}
/* Function to print nodes in a given linked list */
void printList(struct Node *node)
{
while (node!=NULL)
{
printf("%d ", node->data);
node = node->next;
}
}
/* Driver program to test above functions*/
int main()
{
/* Start with the empty list */
struct Node* head = NULL;
/* Let us create a sorted linked list to test the functions
Created linked list will be 11->11->11->13->13->20 */
push(&head, 20);
push(&head, 130);
push(&head, 130);
push(&head, 110);
push(&head, 110);
push(&head, 110);
printf("\n Linked list before duplicate removal ");
printList(head);
/* Remove duplicates from linked list */
removeDuplicates(head);
printf("\n Linked list after duplicate removal ");
printList(head);
return 0;
}
#include <bits/stdc++.h>
using namespace std;
/* Node structure of the linked list nodes */
class Node{
public:
int data;
Node* next;
};
/* Using this function we will be removing the duplicates elements from the given sorted linked list */
void removeDuplicatesSortedList(Node* head){
Node* current = head;
Node* next_next;
if (current == NULL)
return;
while (current->next != NULL){
if (current->data == current->next->data){
next_next = current->next->next;
free(current->next);
current->next = next_next;
}
else{
current = current->next;
}
}
}
/* Using this function we will be pushing a new node at the head of the linked list */
void pushNodeHead(Node** head, int data){
Node* new_node = new Node();
new_node->data = data;
new_node->next = (*head);
(*head) = new_node;
}
/* Using this function we will be printing the linked list */
void printingLinkedList(Node *node){
while (node!=NULL){
cout<<" "<<node->data;
node = node->next;
}
cout<<endl;
}
int main()
{
Node* head = NULL;
pushNodeHead(&head, 35);
pushNodeHead(&head, 30);
pushNodeHead(&head, 12);
pushNodeHead(&head, 10);
pushNodeHead(&head, 10);
pushNodeHead(&head, 10);
cout<<"Linked list before removing duplicates"<<endl;
printingLinkedList(head);
removeDuplicatesSortedList(head);
cout<<"Linked list after removing duplicates"<<endl;
printingLinkedList(head);
return 0;
}
class DeleteDuplicates
{
Node head;
class Node
{
int data;
Node next;
Node(int d) {data = d; next = null; }
}
void removeDuplicates()
{
Node curr = head;
/* Traverse list till the last node */
while (curr != null) {
Node temp = curr;
/*Compare current node with the next node and
keep on deleting them until it matches the current
node data */
while(temp!=null && temp.data==curr.data) {
temp = temp.next;
}
/*Set current node next to the next different
element denoted by temp*/
curr.next = temp;
curr = curr.next;
}
}
void push(int new_data)
{
Node new_node = new Node(new_data);
new_node.next = head;
head = new_node;
}
void printList()
{
Node temp = head;
while (temp != null)
{
System.out.print(temp.data+" ");
temp = temp.next;
}
System.out.println();
}
public static void main(String args[])
{
DeleteDuplicates llist = new DeleteDuplicates();
llist.push(20);
llist.push(13);
llist.push(13);
llist.push(11);
llist.push(11);
llist.push(11);
System.out.println("List before removal of duplicates");
llist.printList();
llist.removeDuplicates();
System.out.println("List after removal of elements");
llist.printList();
}
}
class Node:
def __init__(self, data):
self.data = data
self.next = None
class LinkedList:
def __init__(self):
self.head = None
def push(self, new_data):
new_node = Node(new_data)
new_node.next = self.head
self.head = new_node
def deleteNode(self, key):
temp = self.head
if (temp is not None):
if (temp.data == key):
self.head = temp.next
temp = None
return
while(temp is not None):
if temp.data == key:
break
prev = temp
temp = temp.next
if(temp == None):
return
prev.next = temp.next
temp = None
def printList(self):
temp = self.head
while(temp):
print(temp.data , end = ' ')
temp = temp.next
def removeDuplicates(self):
temp = self.head
if temp is None:
return
while temp.next is not None:
if temp.data == temp.next.data:
new = temp.next.next
temp.next = None
temp.next = new
else:
temp = temp.next
return self.head
llist = LinkedList()
llist.push(35)
llist.push(30)
llist.push(12)
llist.push(10)
llist.push(10)
llist.push(10)
print ("Created Linked List: ")
llist.printList()
print()
print("Linked List after removing",
"duplicate elements:")
llist.removeDuplicates()
llist.printList()
Output
Linked list before removing duplicates
10 10 10 12 30 35
Linked list after removing duplicates
10 12 30 35
Time Complexity: O(n), single traversal of the list require O(n) time, where n is the number of nodes in the linked list.
Conclusion
In this blog, we have seen an approach on how to remove duplicates from sorted list in linear time and haven’t used extra space too. We have also seen the traversing through the linked list in linear fashion.we have understood different types of approaches, dry run and code implementations on how to remove duplicates from sorted linked list. This is a basic problem and is good for strengthening your concepts in LinkedList and if you want to practice more such problems, you can checkout Prepbytes (Linked List).
FAQs on how to remove duplicates from sorted list.
- What are the approaches which are used to remove duplicates from sorted list?
- Approach -1 using Hashmaps.
- Approach -2 using pointers.
- What is the time complexity to remove duplicates from sorted list?
- How is the data stored in the linked list?
There are two known approaches :
The time complexity to remove duplicates from sorted list is O(n).
Each element in the linked list is stored in the form of a node where node is a collection of two parts in which one part is a data part which has a value and the next part is a pointer which stores the address of the next node.