


Last Updated on July 27, 2023 by Mayank Dham

Although linked lists can store unique values, there are situations where duplicates can be present. Hence, the focus of this article is to explain how to remove duplicates from unsorted linked lists.
How to Remove Duplicates from Unsorted Linked List
In this problem, we are given an unsorted LinkedList and are asked to remove the duplicate elements present in the list.
As per the given problem statement, we are presented with an unsorted linked list that potentially includes duplicate elements. Our objective is to eliminate these duplicates from the unsorted linked list.
Let’s try to understand the problem with the help of some examples.
If the given input unsorted linked list is:

- As we can see in the above list, there are multiple occurrences of elements 10, 12 and 11 in the linked list.
- So it means that the list contain duplicates of 10, 12 and 11, and we need to remove these duplicates from the linked list.
- After removing the duplicate elements from the list, the output linked list will be:

If the linked list is: head->10->12->12->15->10->20->20.
- In this case, as we can see in the above list, 10, 12 and 20 are duplicate elements present more than once in the list.
- After removing the duplicate elements from the list, the output will be head->10->12->15->20.
Some more examples:
Sample Input 1: head->2->3->2->4->7.
Sample Output 1: head->2->3->4->7.
Sample Input 2: head->3->3->7->9->7->11->4->9->15.
Sample Input 2: head->3->7->9->11->4->15.
Now, I think from the above examples, the problem statement is clear. So let’s see how we will approach it.
Before moving to the approach section, try to think about how you can approach this problem.
- If stuck, no problem, we will thoroughly see how we can approach the problem in the next section.
Let’s move to the approach section.
Approach 1 (Using two loops) to remove duplicates from unsorted linked list.
Duplicate elements can be removed using two loops:
- Outer loop for traversing the linked list and picking the element of list one by one and inner loop to check if in the rest of the list (starting from outer loop pointer’s next to the end of the list) any duplicate of the element picked up by outer loop is present or not.
- If the duplicate is present in the linked list, remove the duplicate element from the list.
The time complexity for this approach will be O(n2).
- Although the above approach will work fine but if in case the length of our linked list is greater than or equal to 104, it will give us time limit exceed error (TLE).
So to solve the above problem of TLE, we will see in the next approach how using sorting can solve our problem without getting TLE.
Approach 2 (Using merge sort)to remove duplicates from unsorted linked list.
Usually, merge sort is used to sort the linked lists.
- We will sort the linked list by using merge sort.
- And now, all the duplicate nodes will be adjacent, and we can now easily remove these duplicate nodes from the list by comparing the adjacent nodes by iterating the list.
The time complexity for this approach will be O(nLogn), because sorting a list takes (nlogn) time.
Let’s see if we can further reduce the time complexity in the next approach. Any Ideas?
- If not, its okay; we will thoroughly see how to reduce time complexity in the next section.
Let’s move to the next approach.
Approach 3 (Using set)to remove duplicates from unsorted linked list
In this approach, we will make use to set to store the occurrences of the elements of the list.
- The most efficient way to remove the duplicate element is to use a set to store the occurrence of the elements present in the Linked List.
- Now, we traverse the Linked List and if the element in the current node is already present in the set:
- We will remove the current node from the linked list.
- Else we store the element in the set and move forward in the linked list.
Let’s see the algorithm for this approach.
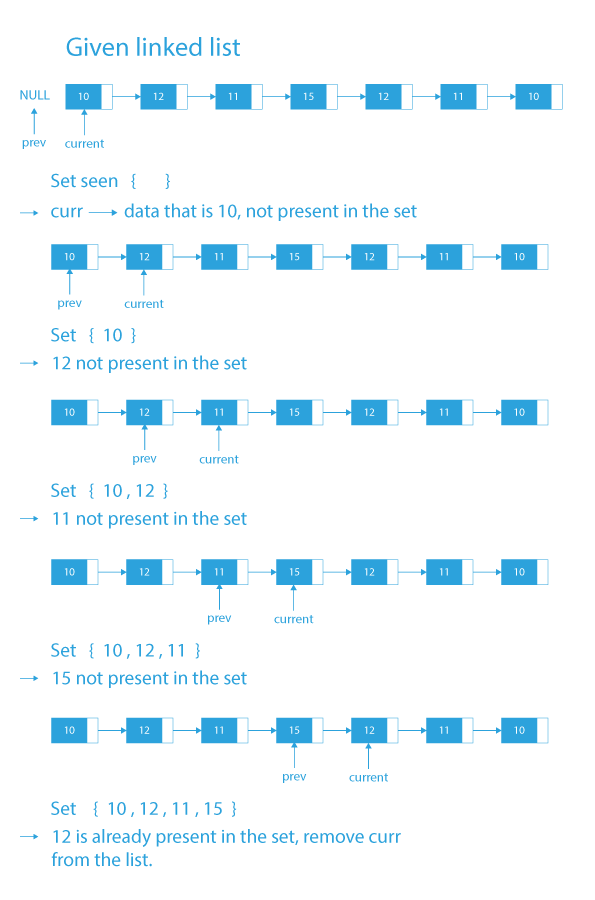
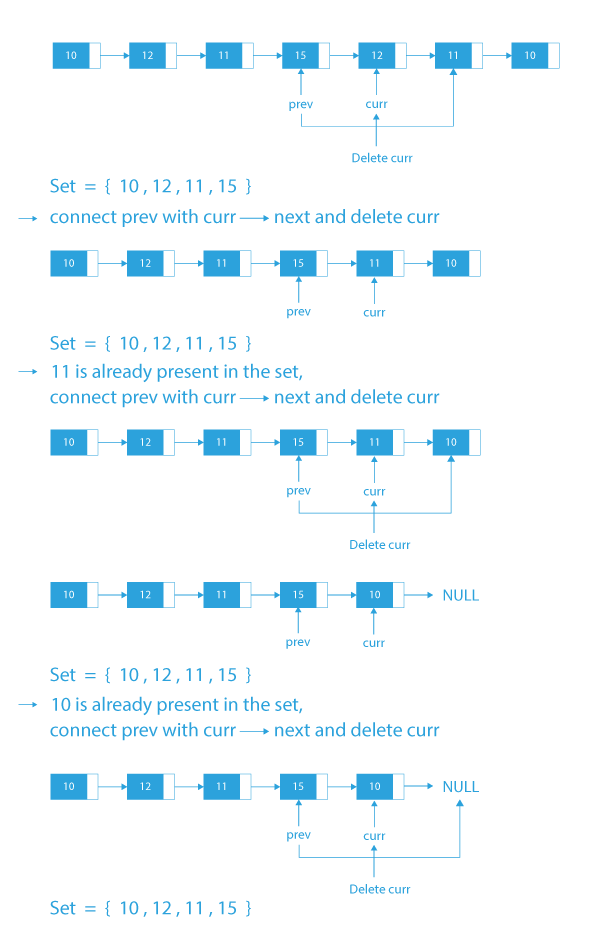
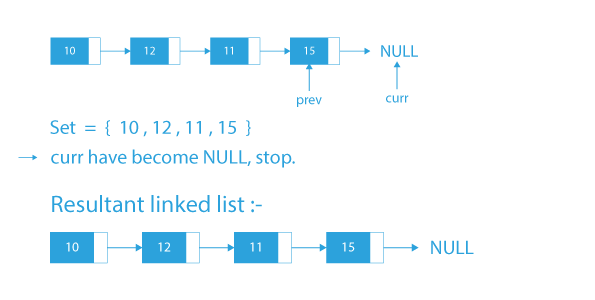
Algorithm to remove duplicates from unsorted linked list
- Take a set seen to store the elements of the Linked List. Also remember that the set stores unique elements.
- Take a variable curr and initialize it with head of the linked list.
- Take a variable prev and initialize it with NULL.
- Traverse the linked list till curr do not become NULL.
- While traversing the list:
- If the element in the current node curr is already present in the set then remove the current node from the linked list by assigning next of curr to the next of previous node of curr (prev->next = curr->next) and delete the node curr.
- Else, insert the element in the set and move prev forward by moving prev to the position of curr.
- Move curr forward by moving curr to the next of prev.
- Finally, after the traversal, our resultant list will be free from duplicates.
Dry Run to remove duplicates from unsorted linked list
Code Implementation to remove duplicates from unsorted linked list
#include<stdio.h>
#include<stdlib.h>
struct Node {
int data;
struct Node* next;
};
// Utility function to create a new Node
struct Node* newNode(int data)
{
struct Node* temp =
(struct Node*)malloc(sizeof(struct Node));
temp->data = data;
temp->next = NULL;
return temp;
}
/* Function to remove duplicates from a
unsorted linked list */
void removeDuplicates(struct Node* start)
{
struct Node *ptr1, *ptr2, *dup;
ptr1 = start;
/* Pick elements one by one */
while (ptr1 != NULL && ptr1->next != NULL) {
ptr2 = ptr1;
/* Compare the picked element with rest
of the elements */
while (ptr2->next != NULL) {
/* If duplicate then delete it */
if (ptr1->data == ptr2->next->data) {
/* sequence of steps is important here */
dup = ptr2->next;
ptr2->next = ptr2->next->next;
free(dup);
}
else /* This is tricky */
ptr2 = ptr2->next;
}
ptr1 = ptr1->next;
}
}
/* Function to print nodes in a given linked list */
void printList(struct Node* node)
{
while (node != NULL) {
printf("%d ", node->data);
node = node->next;
}
}
/* Driver program to test above function */
int main()
{
/* The constructed linked list is:
10->12->11->11->12->11->10*/
struct Node* start = newNode(10);
start->next = newNode(12);
start->next->next = newNode(11);
start->next->next->next = newNode(11);
start->next->next->next->next = newNode(12);
start->next->next->next->next->next = newNode(11);
start->next->next->next->next->next->next = newNode(10);
printf("Linked list before removing duplicates ");
printList(start);
removeDuplicates(start);
printf("\nLinked list after removing duplicates ");
printList(start);
return 0;
}
#include<bits/stdc++.h>
using namespace std;
struct Node
{
int data;
struct Node *next;
};
/* Using this function we will be creating a new node */
struct Node *newNode(int data)
{
Node *temp = new Node;
temp->data = data;
temp->next = NULL;
return temp;
}
/* Using this function we will be removing the duplicates elements from the given unsorted linked list */
void removeDuplicatesFromList(struct Node *head)
{
unordered_set<int> seen;
struct Node *curr = head;
struct Node *prev = NULL;
while (curr != NULL)
{
if (seen.find(curr->data) != seen.end())
{
prev->next = curr->next;
delete (curr);
}
else
{
seen.insert(curr->data);
prev = curr;
}
curr = prev->next;
}
}
/* Using this function we will be printing the linked list */
void printList(struct Node *node)
{
while (node != NULL)
{
printf("%d ", node->data);
node = node->next;
}
}
int main()
{
struct Node *head = newNode(10);
head->next = newNode(12);
head->next->next = newNode(11);
head->next->next->next = newNode(15);
head->next->next->next->next = newNode(12);
head->next->next->next->next->next = newNode(11);
head->next->next->next->next->next->next = newNode(10);
cout<<"Linked list before removing duplicates"<<endl;
printList(head);cout<<endl;
removeDuplicatesFromList(head);
cout<<"Linked list after removing duplicates"<<endl;
printList(head);cout<<endl;
return 0;
}
import java.util.HashSet;
class Unsorted
{
static class node
{
int val;
node next;
public node(int val)
{
this.val = val;
}
}
/* Function to remove duplicates from a
unsorted linked list */
static void removeDuplicate(node head)
{
// Hash to store seen values
HashSet<integer> hs = new HashSet<>();
/* Pick elements one by one */
node current = head;
node prev = null;
while (current != null) {
int curval = current.val;
// If current value is seen before
if (hs.contains(curval)) {
prev.next = current.next;
}
else {
hs.add(curval);
prev = current;
}
current = current.next;
}
}
static void printList(node head)
{
while (head != null) {
System.out.print(head.val + " ");
head = head.next;
}
}
public static void main(String[] args)
{
node start = new node(10);
start.next = new node(12);
start.next.next = new node(11);
start.next.next.next = new node(11);
start.next.next.next.next = new node(12);
start.next.next.next.next.next = new node(11);
start.next.next.next.next.next.next = new node(10);
System.out.println("Linked list before removing duplicates :");
printList(start);
removeDuplicate(start);
System.out.println("\nLinked list after removing duplicates :");
printList(start);
}
}
class Node:
def __init__(self, data):
self.data = data
self.next = None
class LinkedList:
def __init__(self):
self.head = None
def printlist(self):
temp = self.head
while (temp):
print(temp.data, end=" ")
temp = temp.next
def removeDuplicates(self, head):
if self.head is None or self.head.next is None:
return head
hash = set()
current = head
hash.add(self.head.data)
while current.next is not None:
if current.next.data in hash:
current.next = current.next.next
else:
hash.add(current.next.data)
current = current.next
return head
if __name__ == "__main__":
llist = LinkedList()
llist.head = Node(10)
second = Node(12)
third = Node(11)
fourth = Node(15)
fifth = Node(12)
sixth = Node(11)
seventh = Node(10)
llist.head.next = second
second.next = third
third.next = fourth
fourth.next = fifth
fifth.next = sixth
sixth.next = seventh
print("Linked List before removing Duplicates.")
llist.printlist()
llist.removeDuplicates(llist.head)
print("\nLinked List after removing duplicates.")
llist.printlist()
**Output**
Linked list before removing duplicates
10 12 11 15 12 11 10
Linked list after removing duplicates
10 12 11 15
Time Complexity: O(n), where n is the number of nodes in the given linked list.
**Conclusion:**
In conclusion, removing duplicates from an unsorted linked list is a common problem in programming. Through the utilization of efficient algorithms and data structures like hash sets or temporary buffers, we can proficiently detect and eliminate duplicate elements from the linked list. This involves traversing the linked list, comparing each element with the rest, and removing any duplicates encountered. By tackling this issue, we can guarantee the integrity and uniqueness of the data held within the linked list.
## FAQs related to Removing Duplicates from an Unsorted Linked List
Some Frequently asked questions related to remove duplicates from unsorted linked list are:
**Q1: Can we use a sorting algorithm to remove duplicates from an unsorted linked list?**
**Ans.** Yes, it is possible to use sorting algorithms like to merge sort or quicksort to remove duplicates from an unsorted linked list. However, this approach has a higher time complexity compared to using hash sets or temporary buffers.
**Q2: What is the time complexity of removing duplicates from an unsorted linked list?**
**Ans.** The time complexity depends on the approach used. If a hash set or temporary buffer is utilized, the time complexity is O(n), where n is the number of elements in the linked list. However, if sorting algorithms are employed, the time complexity can be O(n log n) or higher.
**Q3: Can we modify the linked list in-place to remove duplicates?**
**Ans.** Yes, it is possible to modify the linked list in-place to remove duplicates. This involves iterating through the linked list and removing duplicates as they are encountered, without using additional data structures. This approach requires careful manipulation of pointers and can have a time complexity of O(n^2).
**Q4: How can we handle the removal of duplicates if the linked list is very large and cannot fit in memory?**
**Ans.** If the linked list is extremely large and cannot fit in memory, external sorting algorithms or disk-based data structures can be employed to handle the removal of duplicates. These techniques involve dividing the linked list into smaller parts and processing them sequentially or by utilizing external storage.