


Last Updated on November 18, 2022 by Prepbytes

We have observed that a linked list might contain elements which repeat themselves in the list. So, now we will look into a program to remove all occurrences of duplicates from a sorted linked list
Problem Statement to remove all occurrences of duplicates from a sorted linked list
In this question, we are given a sorted Singly Linked List. We have to remove all the occurrences of duplicate nodes in the list.
Problem Statement Understanding on how to remove all occurrences of duplicates from a sorted linked list
Let’s try to understand the problem statement with examples.
Suppose if the given sorted list is:
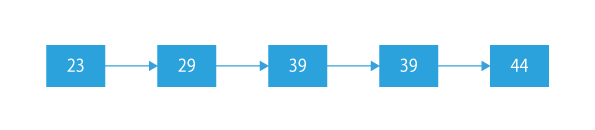
Now, we have to remove all the occurrences of duplicates from this list. As we can see, 39 is the only repeating value (which have more than 1 occurrences in the linked list), so we will delete all the nodes which have the value 39.
So, the final linked list after deletion:
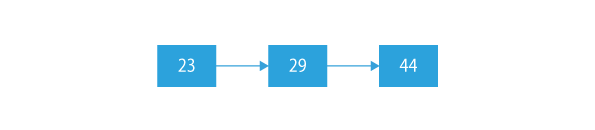
If the given sorted list is:
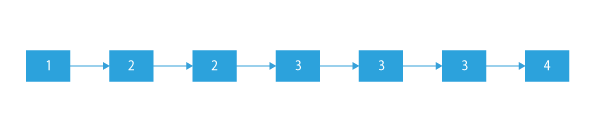
Now, as we can see that 2 and 3 are the only repeating values in the linked list (which have more than 1 occurrences in the linked list) so we will have to remove all the occurrences of 2 and 3 from this list.
So, the final linked list after deletion:
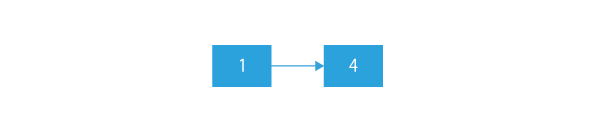
Explanation: All the nodes which appear more than once have been deleted from the input linked list. The only nodes which appear exactly once in the list remain in the list.
This question is not a very complex one. We have to make use of list traversal in the question. Let us have a glance at the approach.
Before moving to the approach, just try to think how you can solve this problem?
Approach on how to remove all occurrences of duplicates from a sorted linked list
The approach is going to be pretty simple. We will maintain a previous pointer which will point to the node just previous to the block of nodes for which we will check for the duplicates, i.e. the previous pointer will point to the last node which has no duplicate.
As long as we will keep finding duplicates, we will keep traversing through the list. As soon as the duplicates end, we will make the previous pointer point to the next of the last duplicate node of that block. Let us have a look at the algorithm.
Algorithm for how to remove all occurrences of duplicates from a sorted linked list
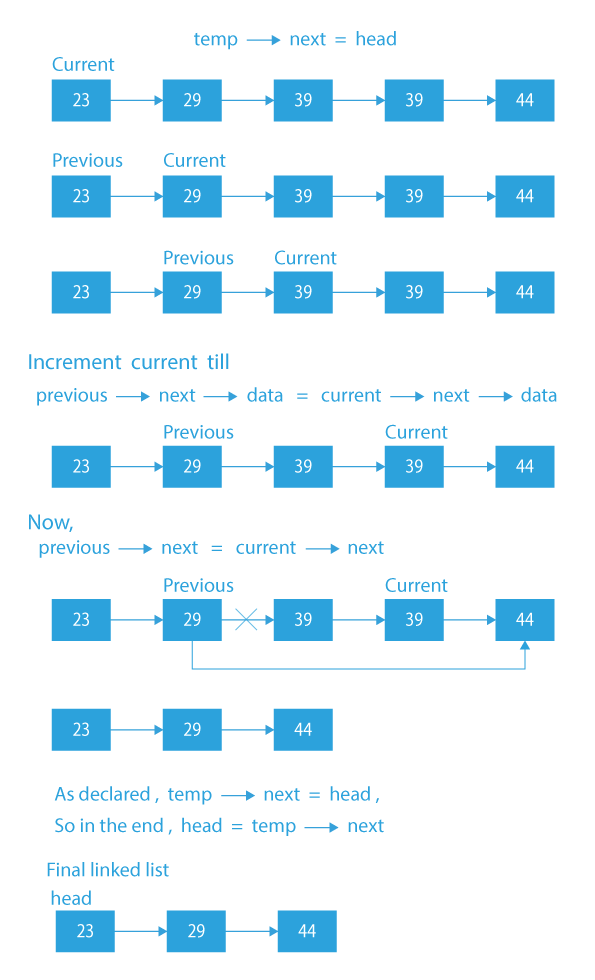
- Create a node dummy which will point to the head of the list, and another node previous which will point to the last node which has no duplicate (initially previous will be pointing to dummy).
- Create another node that will be used to traverse through the list. Let us call this node current.
- Traverse using current till the end of the list.
- Now, as long as the data of next of previous is equal to the data of next of current, increment current by 1.
- If the current stays the same, i.e. no duplicate in the current block, then previous = previous – > next. By doing this, we are just incrementing the previous.
- Else, there are duplicates, so, previous – > next = current – > next. The reason for doing this is that the previous is pointing to the last node which has no duplicates, and the current has been increased, which means there are duplicates. So, we will make the previous point to the next of current in order to remove the duplicates.
- Increment current by one.
- After the traversal, make head point to the next of the dummy node.
Dry Run on how to remove all occurrences of duplicates from a sorted linked list
Code Implementation
#include#include // A Linked List Node struct Node { int data; struct Node* next; }; // Helper function to print a given linked list void printList(struct Node* head) { struct Node* ptr = head; while (ptr) { printf("%d —> ", ptr->data); ptr = ptr->next; } //printf("NULL"); } // Helper function to insert a new node at the beginning of the linked list void push(struct Node** head, int data) { struct Node* newNode = (struct Node*)malloc(sizeof(struct Node)); newNode->data = data; newNode->next = *head; *head = newNode; } // Remove duplicates from a sorted list void removeDuplicates(struct Node* head) { // do nothing if the list is empty if (head == NULL) { return; } struct Node* current = head; // compare the current node with the next node while (current->next != NULL) { if (current->data == current->next->data) { struct Node* nextNext = current->next->next; free(current->next); current->next = nextNext; } else { current = current->next; // only advance if no deletion } } } // Driver Code int main() { // 23->28->28->35->49->49->53->53 struct Node* head = NULL; // create linked list 10->12->8->4->6 push(&head, 16); push(&head, 16); push(&head, 80); push(&head, 12); push(&head, 20); printf("List before removal of duplicates\n"); printList(head); printf("\nList After removal of duplicates\n"); removeDuplicates(head); // print linked list printList(head); return 0; }
#includeusing namespace std; struct Node { int data; struct Node *next; }; struct Node *newNode(int data) { Node *temp = new Node; temp -> data = data; temp -> next = NULL; return temp; } void printList(struct Node *node) { while (node != NULL) { printf("%d ", node -> data); node = node -> next; } } void removeAllDuplicates(struct Node* &start) { Node* dummy = new Node; dummy -> next = start; Node* previous = dummy; Node* current = start; while(current != NULL) { while(current -> next != NULL && previous -> next -> data == current -> next -> data) current = current -> next; if (previous -> next == current) previous = previous -> next; else previous -> next = current -> next; current = current -> next; } // update original head to // the next of dummy node start = dummy -> next; } // Driver Code int main() { struct Node* start = newNode(23); start -> next = newNode(29); start -> next -> next = newNode(39); start -> next -> next -> next = newNode(39); start -> next -> next -> next -> next = newNode(44); cout << "List before removal " << "of duplicates\n"; printList(start); removeAllDuplicates(start); cout << "\nList after removal " << "of duplicates\n"; printList(start); return 0; }
public class LinkedList{
Node head = null;
class Node
{
int val;
Node next;
Node(int v)
{
val = v;
next = null;
}
}
public void insert(int data)
{
Node new_node = new Node(data);
new_node.next = head;
head = new_node;
}
public void removeAllDuplicates()
{
Node dummy = new Node(0);
dummy.next = head;
Node prev = dummy;
Node current = head;
while (current != null)
{
while (current.next != null &&
prev.next.val == current.next.val)
current = current.next;
if (prev.next == current)
prev = prev.next;
else
prev.next = current.next;
current = current.next;
}
head = dummy.next;
}
public void printList()
{
Node trav = head;
if (head == null)
System.out.print(" List is empty" );
while (trav != null)
{
System.out.print(trav.val + " ");
trav = trav.next;
}
}
public static void main(String[] args)
{
LinkedList ll = new LinkedList();
ll.insert(44);
ll.insert(39);
ll.insert(39);
ll.insert(29);
ll.insert(23);
System.out.println("Before removal of duplicates");
ll.printList();
ll.removeAllDuplicates();
System.out.println("\nAfter removal of duplicates");
ll.printList();
}
}
class Node:
def __init__(self, val):
self.val = val
self.next = None
class LinkedList:
def __init__(self):
self.head = None
def push(self, new_data):
new_node = Node(new_data)
new_node.next = self.head
self.head = new_node
return new_node
def removeAllDuplicates(self, temp):
curr = temp
head = prev = Node(None)
head.next = curr
while curr and curr.next:
if curr.val == curr.next.val:
while(curr and curr.next and
curr.val == curr.next.val):
curr = curr.next
curr = curr.next
prev.next = curr
else:
prev = prev.next
curr = curr.next
return head.next
def printList(self):
temp1 = self.head
while temp1 is not None:
print(temp1.val, end = " ")
temp1 = temp1.next
def get_head(self):
return self.head
if __name__=='__main__':
llist = LinkedList()
llist.push(44)
llist.push(39)
llist.push(39)
llist.push(29)
llist.push(23)
print('Created linked list is:')
llist.printList()
print('\nLinked list after deletion of duplicates:')
head1 = llist.get_head()
llist.removeAllDuplicates(head1)
llist.printList()
Output
List before removal of duplicates
23 29 39 39 44
List after removal of duplicates
23 29 44
Space Complexity: O(1), as only temporary variables are being created.
Conclusion
So, in the below article, we have seen how duplicates occur in the linked list and how we remove all occurrences of duplicates from a sorted linked list. It looks like a nested traversal, but it is not. This is an important question when it comes to coding interviews. If you want to solve more questions on Linked List, which are curated by our expert mentors at PrepBytes, you can follow this link Linked List.
FAQs
- What function can remove duplicates?
- Which function removes duplicate values from an array?
- Can we use Hashset to remove duplicates?
Using sort() we can remove duplicates in a list.
Using filter()which creates a new array which have to pass the condition.Accordingly it will return elements.
Basically hashset does not allow any duplicate elements in the list. So, a hashset can be helpful in removing all duplicate values.